PDF Chat Ollama
 Brain Tumor Classification
Brain Tumor ClassificationSetup
Step 1: Install the Requirements
pip install -r requirements.txt
Step 2: Pull the models (if you already have models loaded in Ollama, then not required)
Make sure to have Ollama running on your system from https://ollama.ai
ollama pull mistral
Step 3: put your files in the source_documents folder after making a directory
mkdir source_documents
Step 4: Ingest the files (use python3 if on mac)
python ingest.py
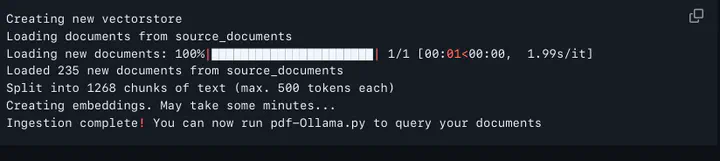
Output should look like this:
Creating new vectorstore
Loading documents from source_documents
Loading new documents: 100%|██████████████████████| 1/1 [00:01<00:00, 1.99s/it]
Loaded 235 new documents from source_documents
Split into 1268 chunks of text (max. 500 tokens each)
Creating embeddings. May take some minutes...
Ingestion complete! You can now run pdf-Ollama.py to query your documents
Step 5: Run this command (use python3 if on mac)
python pdf-Ollama.py
Play with your docs
Enter a query: How many locations does WeWork have?
Try with a different model:
ollama pull llama2:13b
MODEL=llama2:13b python privateGPT.py
Add more files
Put any and all your files into the source_documents directory
The supported extensions are:
.csv: CSV,.docx: Word Document,.doc: Word Document,.enex: EverNote,.eml: Email,.epub: EPub,.html: HTML File,.md: Markdown,.msg: Outlook Message,.odt: Open Document Text,.pdf: Portable Document Format (PDF),.pptx: PowerPoint Document,.ppt: PowerPoint Document,.txt: Text file (UTF-8),
Credits
This code is learned from the Pdf-Chat project by PromptEngineer48